

Data Partitioning


Data partitioning is a technique that splits a database into smaller chunks, both row-wise and column-wise.
One of the main reasons we perform data partitioning is to distribute the load. For example, let's say we have a database with 100 million users. Each user is assigned a unique user_id between 1 and 100 million. Now, we want to access the user data for 15 users whose records are stored between user_ids 60000011 and 60000026.
To get those users, we must query the entire database, which will significantly slow down the process.
What we can do is, to split the 100M record into 5 smaller chunks of database storing 20M records each.
The below image illustrates how we have partitioned the data into 5 smaller databases, with user_id 1 to user_id 2000000 stored in the first partition, user_id 2000001 to user_id 4000000 in the second partition, etc.
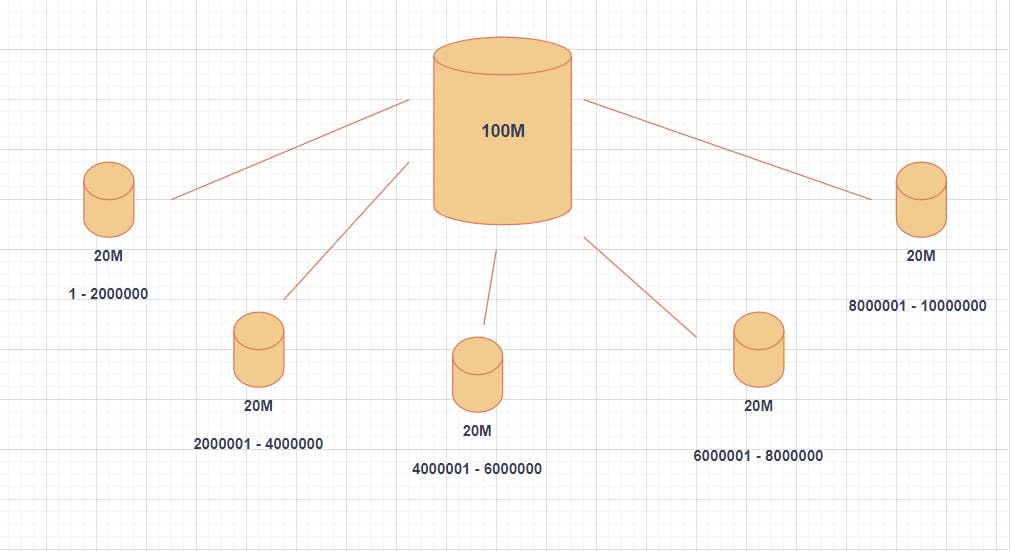
This technique of data partitioning is called horizontal scaling, often referred to as database sharding. In this technique, we do not need to query the whole database to retrieve a few pieces of data. Instead, we can simply go to the partition that stores the particular data we are looking for. In our case, we are looking for user_ids 60000011 to 60000026, so we would go to partition number 4.
While we perform data partitioning, it is important to make use of an appropriate partitioning architecture. Range-based partitioning is what we have used in this article!
Range-based partitioning is a method of dividing data into partitions based on a range of values. When data within a range is queried, the responsible partition will respond. In the above example, we have used range-based partitioning to divide the data into partitions based on the user_id column. The first partition contains user_ids from 1 to 2000000, the second partition contains user_ids from 2000001 to 4000000, and so on.
Here are some additional benefits of data partitioning:
Reduced data redundancy: Data partitioning can help to reduce data redundancy by storing the same data in multiple locations. This can save space and improve performance.
Improved data security: Data partitioning can help to improve data security by isolating sensitive data from other data. This can make it more difficult for unauthorized users to access sensitive data.
Increased flexibility: Data partitioning can make it easier to add new data to a database. This is because new data can be added to a new partition without affecting existing data.
Continuous hashing is another widely used partitioning architecture. We need a separate article to discuss it in more detail.
Conclusion
Data partitioning can also improve scalability by allowing us to distribute the data across multiple servers. This can help us to handle more requests and more data without affecting performance. If you are considering using data partitioning, it is important to weigh the benefits and drawbacks carefully. Data partitioning can be a complex process, and it is important to have a good understanding of your data before you begin.